")
ChatGPT和谷歌的Gemini已经成为领先的大型语言模型的主导力量。很明显,这些平台已经改变了AI行业。然而,它们如何获取信息和管理数据集一直是一个持续的道德问题。
BeInCrypto与Web3中的新兴AI项目进行了交谈,包括ChainGPT、Space ID、Sapien.io、Vanar Chain、O.XYZ、AR.IO和Kindred,讨论了知识产权、版权和所有权的当代关切。一个关键的收获是去中心化人工智能(deAI)作为一个值得考虑的替代方案。
LLMs的崛起和数据获取困境
自从它们被创造以来,大型语言模型(LLMs)已经迅速获得广泛应用。在许多方面,OpenAI的ChatGPT和谷歌的Gemini是公众第一次真正接触到人工智能(AI)能力及其无穷无尽的使用潜力。
然而,这些公司也因其运营受到了审查。为了保持竞争力,AI模型需要访问大量的数据集。LLMs只能通过处理大量文本来生成类人的响应和理解复杂的查询。
为了实现这一目标,OpenAI、谷歌、Meta、微软、Anthropic和英伟达等领先的科技巨头大量汇集了互联网上所有可用的数据和信息来训练他们的AI模型。这种方法引发了严重的问题,即这些平台摄取和后来以输出的形式重复吐出的输入属于谁。
尽管AI具有颠覆性潜力,但知识产权问题却导致了激烈的法律争议。
AI公司是否在建立建立在被盗内容之上的帝国?
AI的快速采用引发了关于数据所有权、隐私和潜在版权侵犯的担忧。一个关键的争议点是使用有版权的材料来训练大公司独家控制的集中式AI模型。
"AI公司正在建立在创作者的背上的帝国,而没有征求许可或分享战利品。作者、艺术家和音乐家花了多年时间完善他们的技艺,结果发现他们的作品被AI模型吞噬,这些模型在几秒钟内就能生成仿制品,"Vanar Chain的CEO Jawad Ashraf告诉BeInCrypto。
这个问题确实引起了广泛的不满。Vanar Chain的CEO补充说,OpenAI和其他公司公开承认刮取有版权的材料,引发了诉讼和更广泛的数据伦理问题。
"问题的关键在于补偿 - AI公司认为刮取公开可用的数据是公平的,而创作者则认为这是白天抢劫,"Ashraf说。
界定AI生成作品的边界
纽约时报于2023年12月对OpenAI和微软提起诉讼,指控他们侵犯版权和未经授权使用其知识产权。
时报指控微软和OpenAI建立了一个以"非法复制和使用时报独特有价值作品"为基础的商业模式。该报还辩称,这些模型"利用并在许多情况下保留了这些作品中包含的可受版权保护的表达"。
四个月后,另外八家在六个不同美国州运营的新闻出版商也起诉了微软和OpenAI侵犯版权。
"法院现在被迫回答几年前还不存在的问题:AI生成的内容是否构成衍生作品?版权持有人在未经同意使用他们的数据时是否可以要求赔偿?"Sapien.io的联合创始人Trevor Koverko告诉BeInCrypto。
除了新闻机构,出版商、作者、音乐家和其他内容创作者也对这些科技公司提起了法律诉讼,指控他们使用了有版权的信息。
跨行业的法律战
就在上周,三个行业团体宣布将在巴黎法院起诉Meta,指控Meta"大规模未经授权使用了受版权保护的作品"来训练其基于生成式AI的聊天机器人助手,这些助手被用于Facebook、Instagram和WhatsApp。
与此同时,视觉艺术家Sarah Andersen、Kelly McKernan和Karla Ortiz起诉了AI艺术生成器Stability AI、DeviantArt和Midjourney使用他们的作品来训练AI模型。
"当涉及到集中式AI公司对数据和创意材料的不受监管使用时,担忧是无穷无尽的。目前,任何拥有公开可用材料的艺术家、作者或音乐家都可能被AI算法抓取,这些算法学会创造出几乎完全相同的内容 - 并从中获利,而艺术家却一无所获,"AR.IO的创始人Phil Mataras说。
OpenAI和谷歌特别辩称,如果立法限制他们获取有版权的材料,美国将在与中国的AI竞争中失去优势。据他们说,中国的公司受到的监管约束较少,这给了他们的竞争对手一个关键优势。
这些强大的公司正在积极游说美国政府将AI对有版权内容的训练归类为"合理使用"。他们坚持认为,AI对有版权内容的处理产生的输出本质上与源材料不同。
然而,随着生成式AI工具越来越多地产生文本、图像和声音,许多行业都在对这些公司提起法律挑战。
"内容创作者 - 无论是作者、音乐家还是软件开发者 - 通常都会说,他们的[知识产权]被以超出合理使用范围的方式使用,尤其是当AI系统复制或复制他们原创作品的某些方面时,"O.XYZ的创始人兼CEO Ahmad Shadid说。
与此同时,在Web3中,参与者正在游说采用一种替代传统公司LLM开发方式的方法。
DeAI成为Web3的替代方案
去中心化AI(deAI)是Web3中一个新兴的领域,探索利用区块链和分布式账本技术创造更民主和透明的AI系统。
"DeAI利用区块链和分布式账本技术,旨在通过创建更透明的AI系统来解决数据所有权和版权问题。它将AI模型的开发和控制分散到全球网络中,建立更公平的AI训练模式,尊重内容创作者的权利。DeAI还旨在提供公平补偿给那些作品被用于AI训练的创作者的机制,从而解决与集中式AI模型相关的许多问题,"Kindred的CEO兼创始人Max Giammario解释道。
随着AI在全球的日益重要,它与区块链的融合必将改变这两个领域,为加密创新和投资开辟新的途径。
为此,行业中的建设者已经开始开发成功的项目,将AI和Web3技术结合起来。
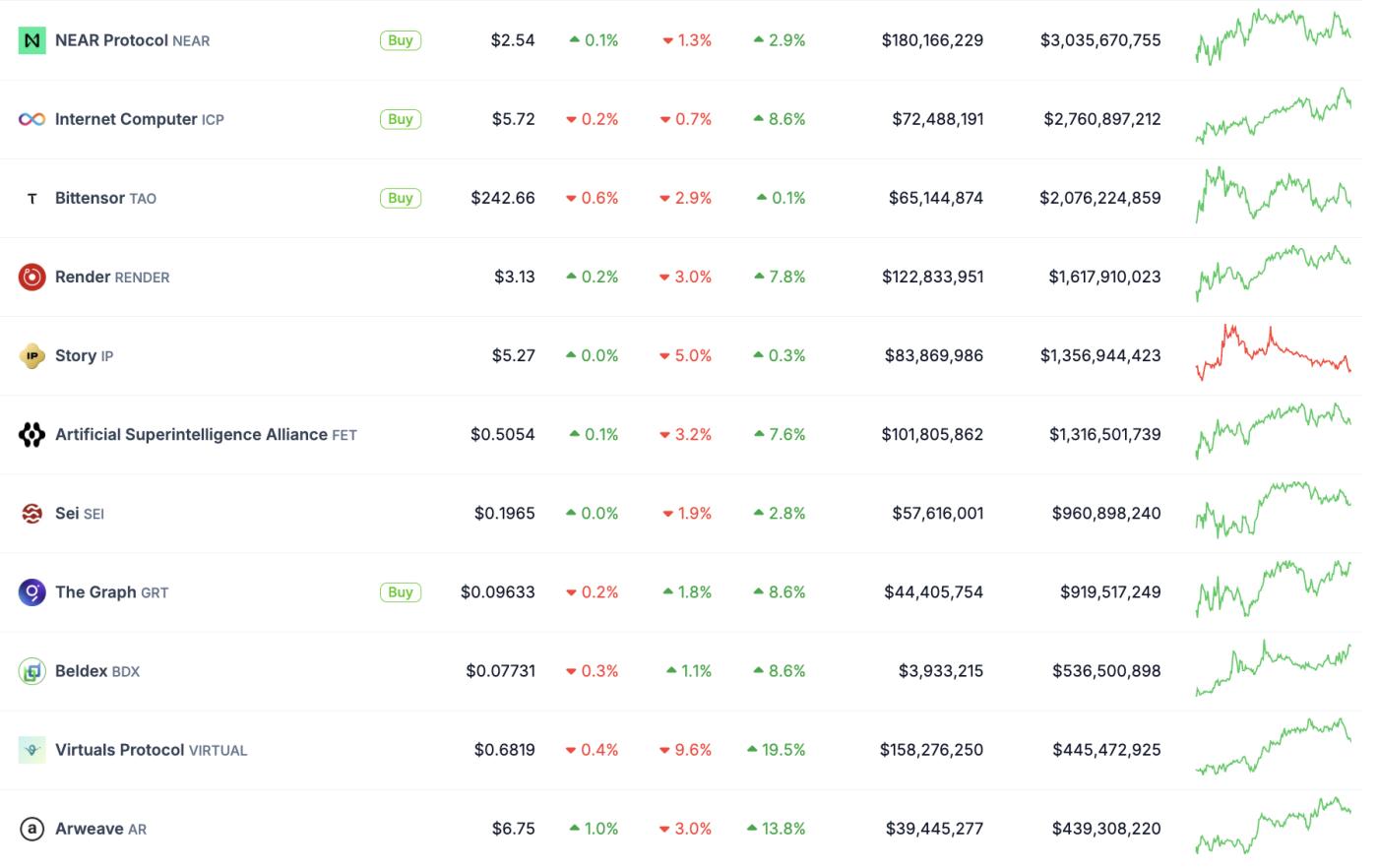
与生产集中式AI模型的公司不同,deAI旨在完全开源。
OpenAI此前曾辩称,尽管使用有版权的材料来训练其AI模型,但它仍符合美国的合理使用原则。此外,它最受欢迎的应用程序ChatGPT是完全免费使用的。
"明确的道德问题是,材料被使用而没有获得创作者的明确许可。如果它们受版权保护,必须获得许可并通常支付费用。但是,即使LLM像ChatGPT使用开源数据,OpenAI的模型也不是开源的。他们使用公开可用的材料,却没有完全"回馈"给他们所吸收的来源。
这里存在一个更广泛的问题,即AI是否应该是开源的。OpenAI的ChatGPT不是,而中国的DeepSeek以及去中心化AI模型是开源的。从伦理和知识产权的角度来看,后者无疑是更好的选择,"Space ID的业务发展总监Harrison Seletsky说。
这些科技巨头的集中式控制也引发了其他关于AI模型实施和监管的担忧。
集中式与去中心化:伦理和操作上的差异
与deAI的社区驱动性质相反,集中式AI模型由少数人建造,这可能导致偏见。
"集中式AI通常在单一的企业伞下运作,决策受到自上而下的利润动机驱动。它本质上是一个由一个实体拥有和管理的黑箱。相比之下,DeAI依赖于社区驱动的方法。AI被设计为分析社区反馈并优化集体利益,而不仅仅是企业利益,"O.XYZ的创始人兼CEO Ahmad Shadid解释道。
与此同时,区块链技术为货币化提供了明确的道路。
"创作者可以将他们的创意资产 - 如文章、音乐甚至想法 - 代币化,并设定自己的价格。这为创作者和知识产权用户创造了一个更公平的环境,本质上形成了一个自由的知识产权市场。这也使所有权很容易证明,因为区块链上的一切都是透明和不可变的,这使得他人在不适当调整激励措施的情况下剥削他人作品的行为变得更加困难,"Seletsky告诉BeInCrypto。
不同的Web3建设者已经开发了去中心化内容用于生成式AI的项目。像Story、Inflectiv和Arweave这样的平台利用区块链技术的各个方面来确保用于AI模型的数据集得到合乎道德的策划。
ChainGPT的创始人Ilan Rakhmanov认为,deAI是对集中式AI的关键反制力量。他断言,解决现有AI垄断的不道德做法将是培养更健康行业的关键。
"这就设立了一个危险的先例,即AI公司可以自由使用有版权的内容而无需适当归属或支付。从法律上讲,这引发了监管审查;从道德上讲,这剥夺了创作者的控制权。ChainGPT相信链上归属和货币化,确保AI用户、贡献者和模型训练者之间存在公平的价值交换,"Rakhmanov说。
但是,要让DeAI成为主角,它首先必须
以下是翻译结果:"集中式AI公司拥有大量计算能力,而去中心化AI需要高效的分布式网络才能扩展。还有数据 - 集中式模型依赖于囤积的数据集,而去中心化AI必须建立可靠的管道来源、验证和公平补偿贡献者,"Koverko告诉BeInCrypto。
就此,Ahmad Shadid补充道:
"在分布式账本上构建和运行AI系统可能很复杂,特别是如果你试图处理大量数据。这也需要仔细监督,以确保AI的学习过程与社区的道德和目标保持一致。"
这些技术巨头也可以利用自己的资源和关系网来大力反对像去中心化AI这样的竞争对手。
"他们可能会通过倡导有利于集中式模型的法规、利用市场主导地位来限制竞争,或控制AI开发所需的关键资源来这样做,"Giammario说。
对于Ashraf来说,这种情况发生的可能性应该是理所当然的。
"当你的整个商业模式建立在囤积数据并秘密变现时,你最不想要的就是一个开放透明的替代方案。预计AI巨头将游说反对去中心化AI,推动限制性法规,并利用其庞大的资源来贬低去中心化替代方案。但互联网本身起初就是一个去中心化的系统,后来被企业接管,人们正在意识到集中控制的弊端。开放AI的战斗才刚刚开始,"Vanar Chain的CEO Jawad Ashraf预期。
然而,为了实现其使命,去中心化AI需要提高其公众认知度,接触Web3用户和非Web3领域的人。
缩小知识鸿沟
当被问及去中心化AI目前面临的主要障碍时,Space ID的Seletsky表示,人们需要意识到AI模型中存在的版权侵犯问题才能解决它。
"主要障碍是缺乏教育。大多数用户不知道数据来自哪里,如何被分析,谁在控制它。许多人甚至不知道AI也存在偏见,就像人类一样。在他们能够理解去中心化AI模型的优势之前,需要教育普通人这一点。"
一旦公众了解了集中式AI模型中存在的版权问题,去中心化AI的倡导者必须积极展示去中心化AI作为强有力替代方案的优点。然而,尽管认知度提高,去中心化AI仍面临着采用挑战。
"采用是另一个挑战。企业习惯于即插即用的AI解决方案,而去中心化AI需要在安全性、透明度和创新方面证明其优势,同时达到同样的易用性水平,"Koverko说。
前进之路:监管清晰和公众信任
在解决教育和可访问性的挑战后,更广泛采用去中心化AI的关键在于建立监管清晰和公众信任。Sapien.io的联合创始人Trevor Koverko补充说,去中心化AI需要配套的监管清晰才能实现这些目标。
"没有明确的框架,去中心化AI项目可能会因法律不确定性而被边缘化,而集中式参与者则会推动有利于其主导地位的政策。克服这些挑战意味着完善我们的技术,证明现实世界的价值,并建立一个推动开放、民主化AI的运动,"他断言。
Shadid同意需要更多的制度支持,并补充说这应该与建立更大的公众信任相结合。
"如果你花了数十年时间完善专有方法,透明度可能会让人不安,所以去中心化AI必须在信任和创新方面证明其优越性。另一个障碍是建立足够的用户信任和监管清晰,使人们甚至政府都感到舒适地处理数据。获得市场份额的最佳方式是展示现实世界的用例,在这里去中心化AI明显优于其集中式对应物,或至少在速度、成本和质量方面与之匹敌,同时更加开放和公平,"Ahmad Shadid解释道。
最终,围绕AI模型的版权问题需要一种范式转变,重点是尊重知识产权,促进一个更民主的AI生态系统,而不管去中心化AI的最终影响如何。
文章声明:以上内容(如有图片或视频亦包括在内)除非注明,否则均为谈天说币原创文章,转载或复制请以超链接形式并注明出处。